판다스 기초 공부 04. 데이터프레임 행열 추가 수정 삭제. 지금까지 판다스 데이터프레임 행열 이름을 변경하는 방법과 인덱싱과 슬라이싱 방법을 배웠는데, 아직까지 기초다. 이 포스트에서도 가장 기본이 되는 행열에 데이터를 추가하거나 수정, 삭제하는 방법을 배우도록 하겠다.
판다스 데이터프레임
행열 추가 수정
판다스 데이터프레임에 행열을 추가하는 방법과 수정하는 방법은 딕셔너리 자료형과 똑같다. 딕셔너리 자료형에서 객체[ 키 ]에 값을 대입을 할 때 키가 기존에 존재하는 키라면 수정이 되고, 키가 없다면 추가가 된다. 데이터프레임에는 키 대신 행열 이름이 들어갈 뿐이다.
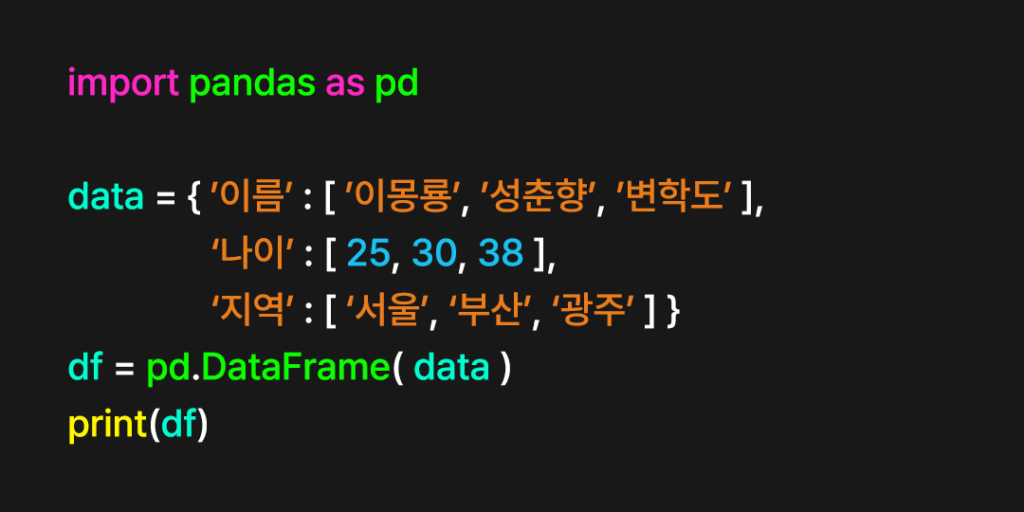

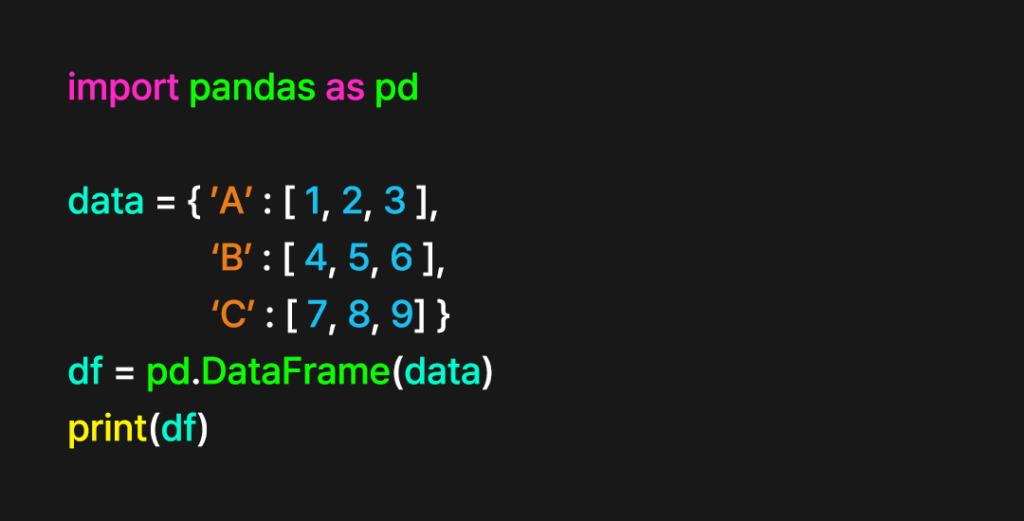
먼저 위와 같이 간단한 데이터프레임을 생성한다.
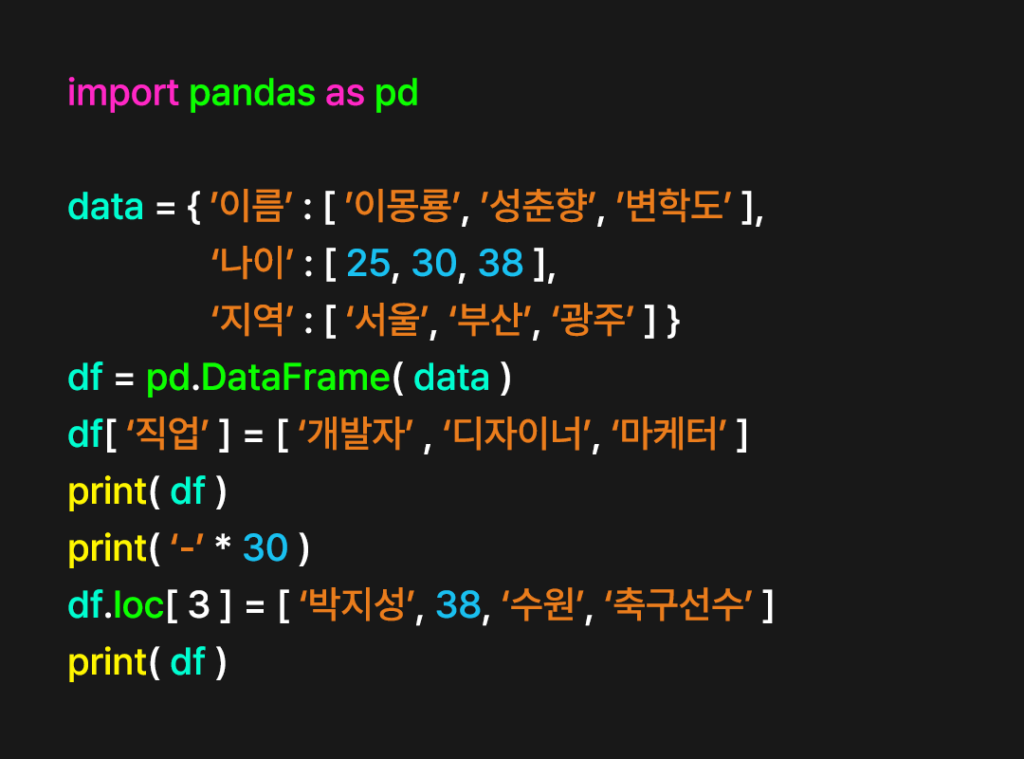
‘직업’이라는 열을 추가하겠다. 열 추가는 딕셔너리 자료형을 추가하는 방법과 동일하다.
df[ ‘직업’ ] = [ ‘개발자’, ‘디자이너’, ‘마케터’ ]
print( df )
print( ‘-‘ * 30 )
다음으로 행을 추가하겠다. 행을 추가할 때는 행 이름을 기반으로 객체.loc 속성을 사용한다.
df.loc[ 3 ] = [ ‘박지성’, 38 ‘수원’, ‘축구선수’ ]
print( df )
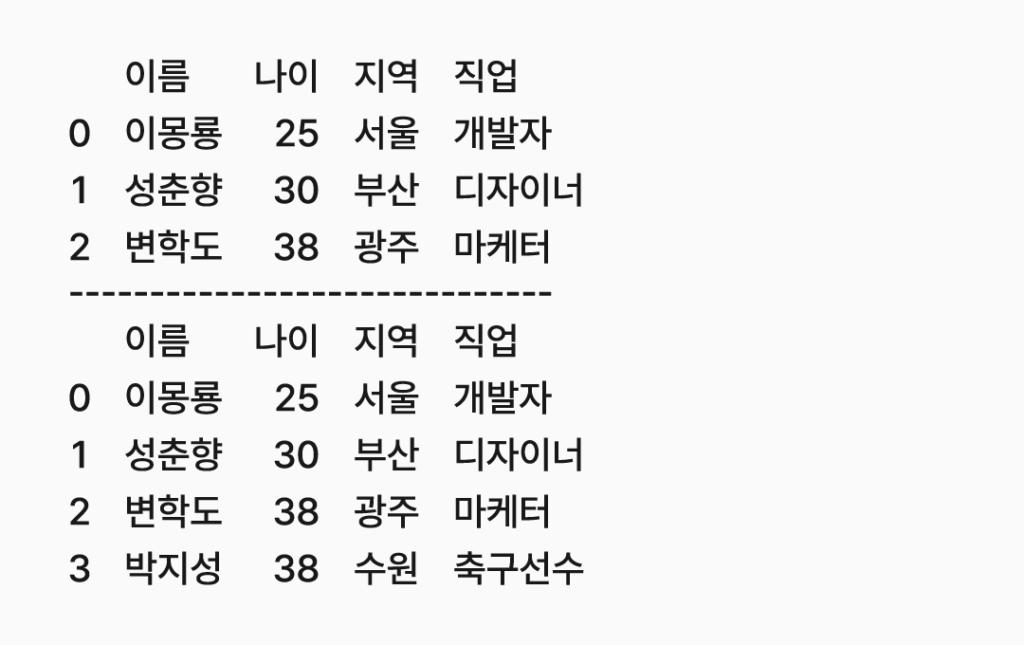
코드를 실행하면 열과 행이 추가된 것을 확인할 수 있다.
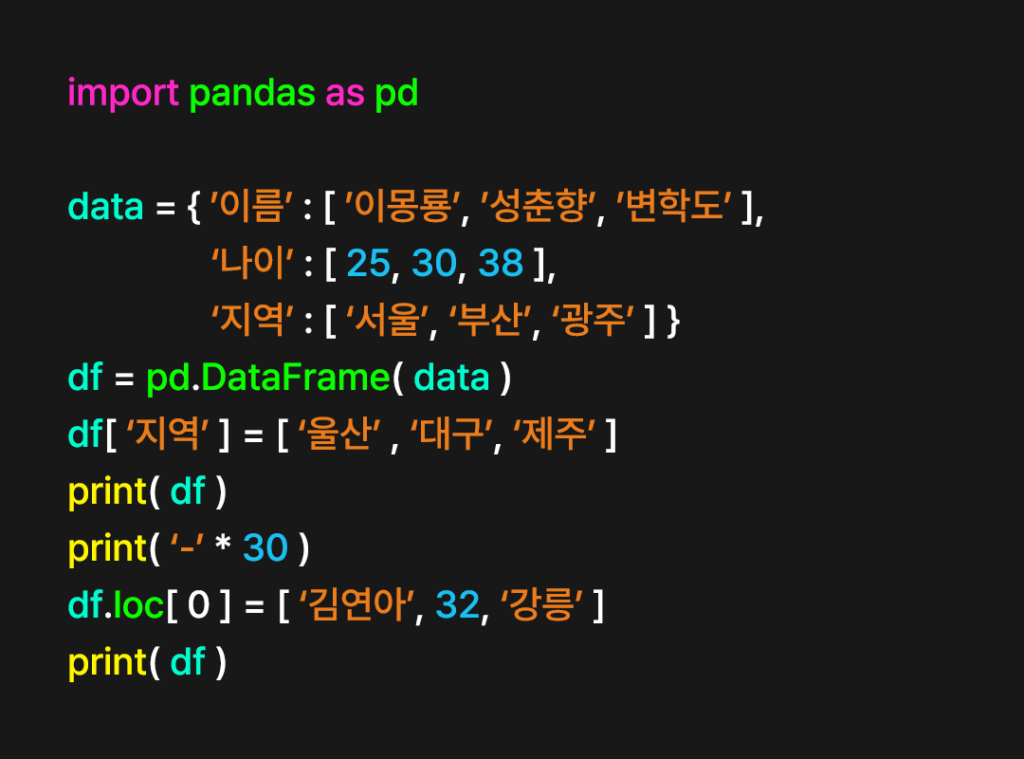
수정하는 방법은 추가와 똑같다. 다만 기존에 정의된 열 이름과 행 이름을 알아야 한다.
열 ‘지역’을 수정한다.
df[ ‘지역’ ] = [ ‘울산’, ‘대구’, ‘제주’ ]
print( df )
print( ‘-‘ * 30 )
다음으로 행 이름 ‘0’을 수정한다.
df.loc[ 0 ] = [ ‘김연아’, 32, ‘강릉’ ]
print( df )
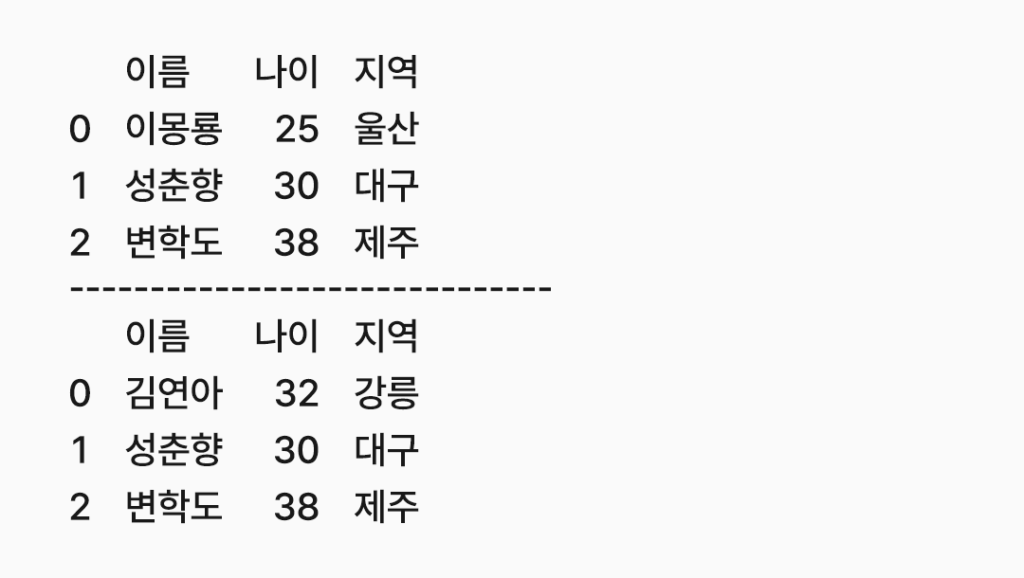
코드를 실행하면 위와 같은 결과를 얻을 수 있다.
다만 위 방법은 전체 열과 전체 행을 수정하는 방법으로, 개별 데이터의 값을 수정하고 싶다면 개별 데이터를 인덱싱한 다음 대입하는 식으로 수정해야 한다. 예를 들어 위 데이터프레임에서 김연아의 나이를 32에서 28로 수정하고 싶다면,
df.loc[ 0 ][ ‘나이’ ] = 28
위와 같이 코드를 작성하면 된다.
판다스 데이터프레임
행열 삭제
행과 열을 삭제하려면 drop 메서드가 필요하다. 행을 삭제할 때는 axis 옵션을 0으로, 열을 삭제할 때는 axis 옵션을 1로 입력한다. drop 속성은 기존 객체를 변경하지 않으므로 원본을 수정하려면 inplace = Ture 옵션을 추가해야 한다.
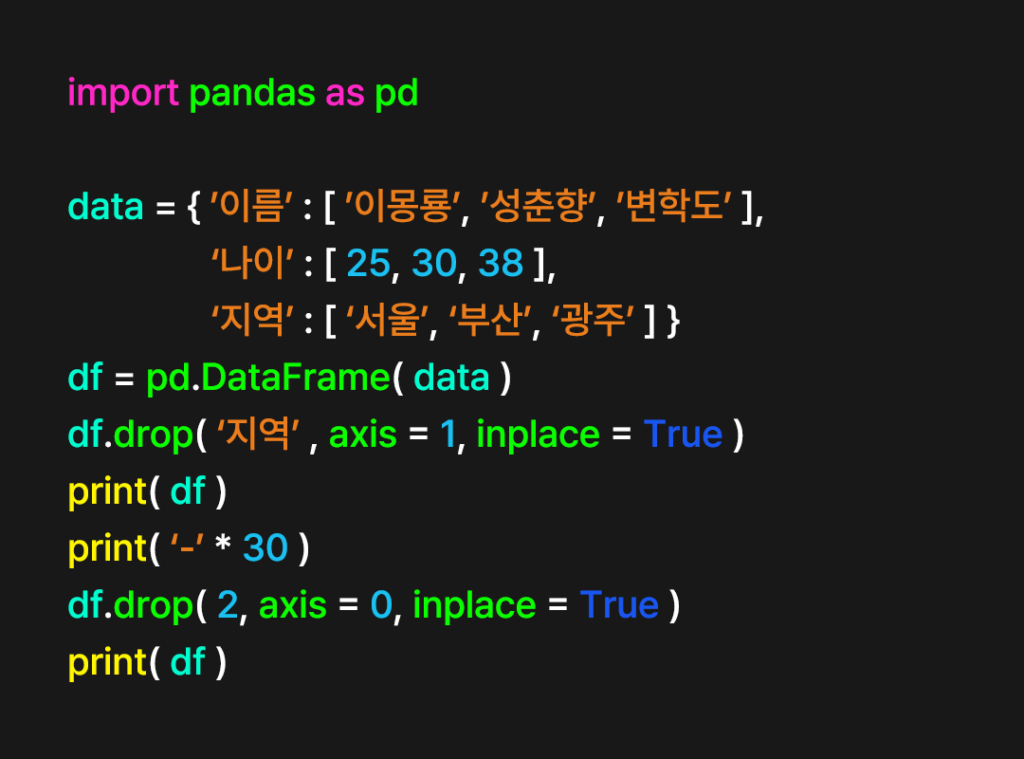
열 ‘지역’을 삭제한다.
df.drop( ‘지역’, axis = 1, inplace = True )
print( df )
행 ‘2’를 삭제한다.
df.drop( 2, axis = 0, inplace = True )
print( df )

코드를 실행하면 위와 같이 행열이 삭제된 것을 확인할 수 있다. 여러 행열을 삭제하려면 대괄호를 이용해 리스트 형식으로 삭제할 목록을 작성하면 된다.
추천 포스트
데이터프레임 행열 인덱싱과 슬라이싱
링크: https://k-man.kr/3445